
How Predictive Analytics Enhances SRE Practices
Predictive analytics is reshaping Site Reliability Engineering (SRE) by helping teams prevent issues before they escalate into failures. Instead of reacting to outages, SRE teams now rely on machine learning models to predict potential problems, reduce downtime, and optimize resources.
Key takeaways:
- Early Issue Detection: Predictive tools identify problems 30–45 minutes before they impact users, minimizing downtime by up to 95%.
- Faster Recovery: AI-driven platforms cut Mean Time to Resolution (MTTR) by 90%.
- Cost Efficiency: Resource optimization reduces cloud infrastructure costs by 20–40%.
- Improved Security: Early anomaly detection flags risks and prevents vulnerabilities.
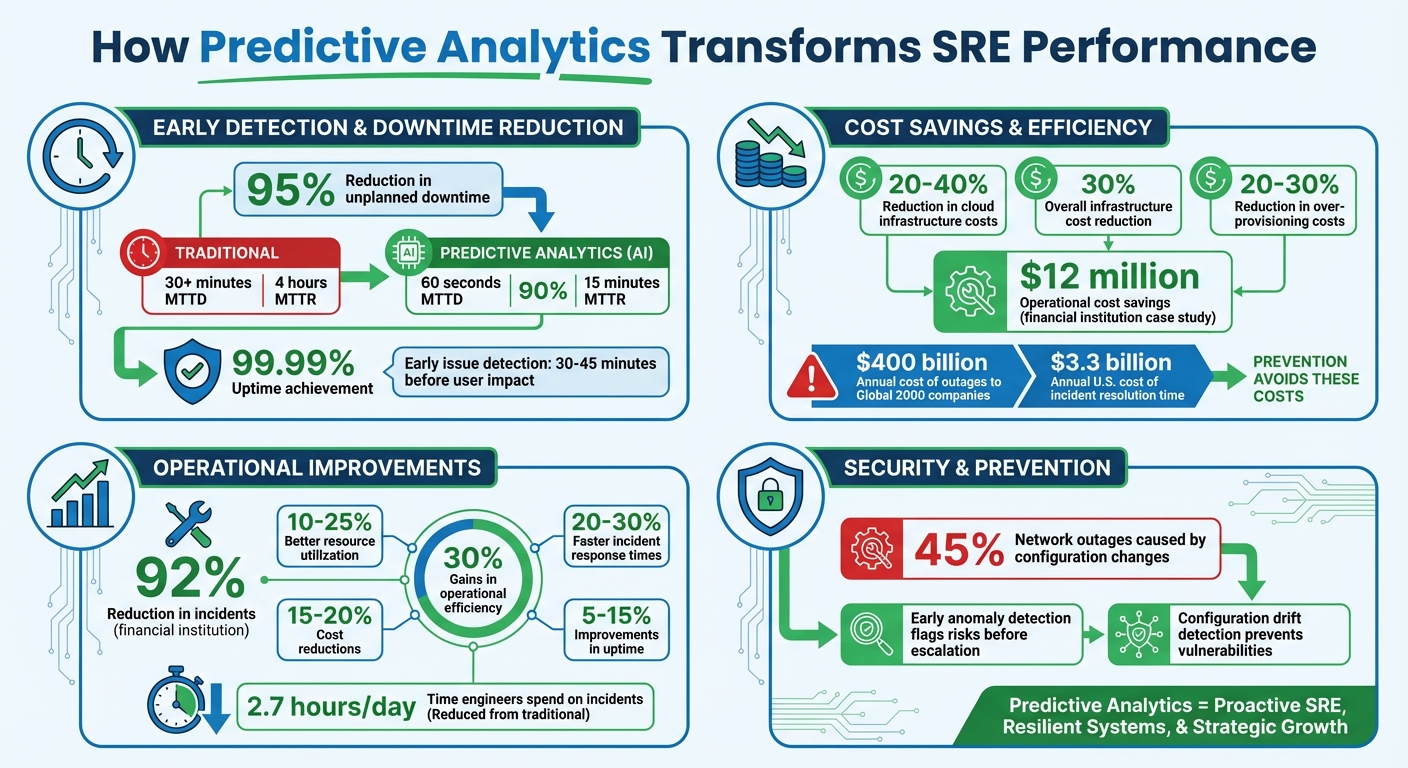
Predictive Analytics Impact on SRE: Key Performance Metrics and Cost Savings
The Future of SRE: Integrating AI for Automated Problem Solving & System Optimization
sbb-itb-3b7b063
How Predictive Analytics Works in SRE
Predictive analytics in SRE turns raw telemetry into insights that teams can act on. It starts with data collection, where SRE teams gather information from sources like system logs, user traffic patterns, performance metrics, and container statuses (e.g., Kubernetes pod restarts, CPU, and memory usage).
Data Collection and Integration
The first step is creating a unified data environment. This involves setting up automated systems to capture metrics and events from every layer of the system. APIs are used to pull real-time data from various databases and cloud platforms. The collected data is then sent to centralized repositories - such as data warehouses like Google BigQuery or data lakes - for analysis. Before the analysis begins, the data is cleaned to remove anomalies, fill in missing points, and eliminate outliers that could distort predictions. For Kubernetes setups, a predictive scan might process seven days of historical data at five-minute intervals, resulting in over 2,000 data points per pod for training models.
To ensure consistency, teams create a semantic layer - a shared set of definitions and logic for metrics. Without this, engineering and operations teams might interpret data differently, leading to confusion and inefficiency. Once the data is cleaned and unified, machine learning models extract patterns and insights.
Machine Learning and Anomaly Detection
Machine learning algorithms play a critical role in analyzing the data. Techniques like unsupervised anomaly detection - including Isolation Forest, Autoencoders, and K-means clustering - spot outliers in real-time data, such as unusual spikes in request latency or error rates, without requiring manual threshold adjustments. Time-series models like ARIMA or Prophet are used to forecast resource behavior, predicting potential failures 30–45 minutes before they affect users. For instance, instead of waiting for pod restarts to hit a hard limit, these models can detect patterns of increasing restarts, allowing teams to investigate before the system becomes unstable.
Advanced AI tools go beyond recognizing patterns. They analyze system topology to find causal relationships between alerts and telemetry data. This capability allows SRE teams to address issues early, preventing minor degradations from escalating into significant failures.
Real-Time Monitoring and Alerts
Predictive models are integrated into monitoring tools like Prometheus, where scoring engines evaluate metrics through APIs. When concerning trends are detected, alerts are triggered via webhooks (e.g., AlertManager), giving teams a heads-up while the system is still in a manageable state. Unlike traditional alerts, which often activate during or after a failure, predictive systems notify teams during the early stages of degradation. This timing ensures logs are cleaner and metrics are easier to act on.
To reduce alert fatigue, a deduplication layer filters out redundant notifications, so teams aren’t overwhelmed by multiple alerts for the same issue. In fast-changing environments, retraining models frequently - ideally daily - helps combat model drift caused by frequent deployments. This approach gives SRE teams the tools they need to act quickly, keeping systems stable and minimizing downtime.
Benefits of Predictive Analytics in SRE
Shifting from reactive to predictive Site Reliability Engineering (SRE) brings tangible benefits, particularly in reducing downtime, cutting costs, and enhancing security. Companies leveraging AI-powered predictive tools experience fewer incidents, faster recovery, and significant savings.
Reduced Downtime
Predictive analytics allows SRE teams to identify issues 30–45 minutes before they impact users. Machine learning models establish baselines for normal system behavior, detecting anomalies hours - or even days - before they escalate. This early detection helps teams resolve problems while logs and metrics remain clear.
The results? Organizations using AI-driven SRE platforms report a 95% drop in unplanned downtime. Tools powered by natural language processing and knowledge graphs can pinpoint root causes almost instantly, slashing investigation times from 45 minutes to under 10 minutes. By cross-referencing incidents with deployment history and configuration changes - responsible for 45% of network outages - these systems help engineers address issues before they spiral.
"Organizations using AI-powered SRE platforms report a 90% reduction in mean time to resolution (MTTR) and a 95% decrease in unplanned downtime." - Abilytics Labs
AI-powered systems also reduce Mean Time to Detection (MTTD) to under 60 seconds, compared to over 30 minutes with traditional monitoring. Considering that outages cost Global 2000 companies around $400 billion annually, even minor reductions in downtime translate to massive savings. These improvements not only enhance system reliability but also free up resources for other priorities.
Cost Savings and Resource Optimization
Predictive analytics helps eliminate wasteful over-provisioning. When organizations lack visibility into actual demand, they often allocate 60–70% more resources than necessary to avoid outages. Machine learning models like ARIMA or Prophet analyze traffic patterns and seasonal trends, enabling proactive scaling that balances uptime with cost efficiency.
By adopting predictive strategies, companies can reduce over-provisioning costs by 20–30% and lower overall infrastructure expenses by 30%. AI-driven tools ensure that resources are allocated based on actual needs, cutting compute costs by 20–40%. When paired with container orchestration platforms like Kubernetes, teams can achieve up to a 40% reduction in cloud infrastructure costs compared to traditional setups.
Predictive analytics also minimizes operational toil. Automated root cause analysis and anomaly detection replace time-consuming manual investigations, often referred to as "TicketOps." Engineers spend an average of 2.7 hours per day resolving incidents, costing U.S. companies approximately $3.3 billion annually. Automating routine tasks like restarting failed pods or scaling deployments allows teams to focus on strategic projects. Organizations adopting these practices report a 15% boost in operational efficiency.
Key outcomes include:
- 10–25% better resource utilization
- 15–20% cost reductions
- 20–30% faster incident response times
- 5–15% improvements in uptime
- Up to 30% gains in overall operational efficiency
Improved Security
Predictive analytics doesn’t just improve operations - it also bolsters security by catching threats early. AI systems analyze authentication flows, authorization policies, and network activity to flag potential security incidents before they escalate. For example, machine learning tools can differentiate between legitimate traffic surges and possible attacks, providing critical insights in fast-paced environments.
Configuration drift detection further enhances security by identifying unauthorized changes that could lead to vulnerabilities, addressing a major cause of network outages (45%). Advanced tools like eBPF probes offer deep visibility into system-level activity, such as TCP retransmissions and suspicious system calls, that traditional monitoring might overlook.
When high-risk anomalies are detected, these systems automatically notify security engineers and trigger remediation playbooks. Predictive analytics also evaluates the impact of code deployments and infrastructure updates before they go live, identifying risky changes that could compromise security. This proactive approach ensures security remains a core focus throughout the deployment process.
"The monitoring tools tell you something is wrong, while AI SRE tools tell you why it's wrong and what to do about it." - Ilan Adler, Komodor
Case Studies and Applications
Real-world examples highlight how predictive analytics can transform Site Reliability Engineering (SRE). Across industries, organizations have successfully used these tools to prevent outages, streamline operations, and automate incident responses. These case studies show how measurable improvements in uptime and cost efficiency are achieved through proactive strategies.
IT Infrastructure Optimization
In February 2026, a top financial institution implemented AI-driven SRE for its payment processing systems. The results were impressive: a 92% reduction in incidents, US$12 million in operational cost savings, and a drastic drop in Mean Time to Recovery (MTTR) from 4 hours to just 15 minutes.** All this while maintaining 99.99% uptime.
Another example comes from a major retailer that used predictive models to tackle seasonal demand spikes. By analyzing historical sales data and user traffic trends, they accurately forecasted resource needs for peak events like Black Friday. The result? A 30% reduction in cloud costs and 99.9% uptime during their busiest sales periods. Similarly, a global SaaS provider leveraged algorithms to predict user engagement and system loads. This led to a 20% increase in customer retention and a 15% boost in user satisfaction, thanks to proactive resource adjustments. These cases showcase how AI enables teams to address potential challenges before they escalate, ensuring smooth operations.
Preventing Outages in Cloud Environments
Predictive analytics plays a crucial role in preventing small issues from snowballing into full-blown outages. Cloud providers now use these tools to predict hardware failures and schedule maintenance during off-peak hours. Real-time anomaly detection can identify issues like memory leaks or CPU contention 30–45 minutes before they become critical, effectively stopping cascading failures.
AI also helps by correlating configuration drifts with recent deployments, offering immediate fixes for one of the leading causes of system instability. Advanced capacity planning models, such as ARIMA and Prophet, provide forecasts of resource exhaustion days in advance. This prevents crashes caused by running out of disk space or memory. By shifting from reactive to proactive monitoring, predictive analytics completely changes how SRE teams manage their systems.
AI-Powered SRE Automation
Kanu AI stands out as a prime example of how automation can revolutionize SRE workflows. Its specialized agents collaborate to translate product requirements into production-ready systems. The platform's Intent Agent, DevOps Agent, and QA Agent perform over 250 validation checks on live systems, analyze logs and metrics for diagnostics, and even generate pull requests with complete application and infrastructure code. This level of automation not only streamlines processes but also supports proactive SRE by identifying and resolving issues before users are impacted.
"AI SRE is a system that understands your infrastructure topology, learns the relationships between your services, and takes autonomous action when things break or drift from optimal states." - Ilan Adler, Komodor
These examples underline how predictive analytics and AI-powered tools are reshaping SRE, helping teams anticipate challenges, minimize disruptions, and maintain optimal performance.
How to Implement Predictive Analytics in SRE
Shifting from reactive monitoring to predictive Site Reliability Engineering (SRE) involves a deliberate and structured approach. By focusing on three key steps - consolidating data, training models on historical patterns, and automating responses - you can unlock the potential of predictive analytics.
Building Unified Data Environments
To make predictive analytics work, you need a unified view of your system's telemetry. This means consolidating logs, metrics, traces, and topology data into one cohesive environment. Without this, AI models lack the full context they need to analyze system behavior effectively.
Tools like OpenTelemetry can standardize your data collection process. Since it's vendor-neutral, OpenTelemetry ensures flexibility, allowing you to avoid being tied to a single monitoring platform. For deeper insights, consider using eBPF probes like Pixie to gather kernel-level data - such as network latency and system calls - without altering your application code.
Once your data is collected, store it in high-cardinality time-series databases like VictoriaMetrics or M3DB. These databases can handle millions of unique data streams, making them ideal for granular, pod-level analysis. For example, you could plan a four-week sprint to streamline this process:
- Week 1: Audit your current monitoring setup.
- Week 2: Unify data using OpenTelemetry.
- Week 3: Implement anomaly detection for critical services.
- Week 4: Develop a custom operator to address a common failure mode.
This foundation is critical for accurate anomaly detection and proactive incident management.
Training AI Models on Historical Logs
With a unified data environment in place, the next step is training predictive models. To do this effectively, you'll need at least 12 to 15 months of historical performance data. This ensures models can account for recurring patterns, like holiday traffic spikes or end-of-quarter business surges.
It's not just about raw data - context matters. Enhance your dataset with variables like user behavior trends, marketing campaigns, seasonal shifts, and even external events like holidays. Different SRE goals require different algorithms:
- ARIMA or Prophet for time-series forecasting.
- Random Forest or Gradient Boosting for predicting resource demand.
- Isolation Forest or Autoencoders for detecting anomalies.
For example, Random Forest models can achieve over 90% accuracy in capacity planning, provided your dataset includes at least 100 examples of each failure mode you're targeting. However, as your infrastructure evolves, models can drift. To maintain accuracy, create continuous learning loops that retrain models after major updates or feature deployments. Involving your SRE team in defining variables and causal relationships is key - they can help filter out irrelevant data that might mislead the models.
Automating SRE Pipelines with AI Agents
Once your models are trained, it's time to put them to work by automating responses. Modern AI agents go beyond summarizing data - they simulate human reasoning by forming hypotheses, validating them with live telemetry, and digging deeper to identify root causes.
"If a human operator needs to touch your system during normal operations, you have a bug. AI should be the primary operator for known and recurring operational tasks."
Start small by automating low-risk tasks, like restarting failed pods or scaling resources. Once these processes prove reliable, you can move on to automating higher-risk actions, such as rolling back databases or shifting traffic. To integrate automation, use tools like ArgoCD or Flux alongside Kubernetes Operators, enabling your AI agents to trigger actions when anomalies are detected.
For example, platforms like Kanu AI demonstrate how automation can transform SRE workflows. Kanu AI uses three specialized agents that:
- Perform over 250 live system validation checks.
- Analyze logs and metrics to diagnose issues.
- Generate pull requests with complete application and infrastructure code.
This level of automation helps prevent incidents from escalating into user-facing problems, aligning perfectly with a proactive SRE approach.
To ensure your automation stays effective, regularly test it using chaos engineering. Tools like Chaos Mesh allow you to simulate failures, helping you validate whether your models can accurately detect and predict these scenarios. This ongoing validation ensures your AI agents keep pace with changes in your infrastructure, maintaining their reliability over time.
The Future of Predictive Analytics in SRE
Key Takeaways
Predictive analytics is changing the game for Site Reliability Engineering (SRE) by shifting the focus from reacting to problems to preventing them altogether. Organizations using predictive analytics report major improvements, including better uptime and lower mean time to recovery (MTTR). It also helps cut costs by fine-tuning resource allocation and reducing unnecessary spending. On top of that, spotting anomalies early strengthens security by flagging potential threats before they become serious. The combined benefits - less downtime, smarter spending, and stronger security - make a strong case for its adoption.
What's Next for Predictive SRE
With these benefits already in play, the future of SRE is moving toward systems that are even smarter and more independent.
In the next ten years, a big shift is expected from traditional automation to what experts are calling "Agentic AI." These systems will not just follow pre-set rules - they’ll be able to plan, reason, and learn on their own, continuously adapting as they go. Future SRE workflows could lean heavily on multi-agent systems (MAS), where specialized AI agents work together using communication protocols to solve complex infrastructure issues.
"Agentic AI offers a paradigm shift in SRE, transforming operations from reactive to proactive, intelligent, and autonomous." – Rajendra Pachouri, Solution Architect
Taking automation to the next level, Agentic AI introduces systems capable of making decisions and improving themselves without constant human input. One exciting development in this space is the push for zero-downtime operations. This will be made possible by integrating advanced telemetry tools like OpenTelemetry and eBPF, which could cut mean time to detection (MTTD) to under 60 seconds. Predictive autoscaling is also expected to become more advanced, moving away from static thresholds to real-time resource management powered by reinforcement learning. Beyond that, reliability is expected to "shift left", meaning AI will help optimize system architecture and predict potential issues during the design phase, long before they reach production.
However, there are challenges to overcome. Maintaining high-quality data, addressing model drift as systems grow and change, and ensuring trust with explainable AI are all hurdles that need to be tackled. Organizations that focus on solid data practices, embrace gradual automation, and test their systems through chaos engineering will be better equipped to take advantage of these advancements. These challenges are likely to inspire the next wave of innovation in AI-driven SRE practices.
FAQs
What data do I need to start predictive SRE?
To kick off predictive Site Reliability Engineering (SRE), start by collecting essential data on how your system behaves and performs. This means diving into both historical and real-time metrics, like logs, traffic patterns, resource consumption, and past incidents. Time series data plays a crucial role here - it helps spot trends and seasonal shifts in your system's performance. With this information, machine learning models can predict potential issues, while real-time monitoring and alerts allow you to catch anomalies early and handle them before they escalate.
How do we prevent model drift after frequent deployments?
To keep models performing as expected, it's crucial to integrate continuous monitoring and data drift detection into your Site Reliability Engineering (SRE) workflows. Here's how:
- Real-time performance tracking: Monitor how your models are performing in real-time. This helps you quickly spot any deviations from expected behavior.
- Data distribution checks: Compare new incoming data with the original training data. If the distributions start to differ, it might signal that the model needs attention.
- Regular retraining: Keep your models updated by retraining them with fresh, relevant data. This ensures they stay aligned with current conditions.
- Automated validation: Use automated checks to validate model updates before deploying them into production.
- AI-powered tools: Leverage tools that analyze logs and metrics to identify potential issues early. These tools can send proactive alerts, helping teams address problems before they escalate.
By incorporating these practices, you can ensure your models stay accurate and continue to meet operational needs.
Which SRE tasks should we automate first with AI?
When it comes to reliability, focusing on automating proactive monitoring, capacity planning, and incident response is key. With AI-powered predictive analytics, systems can analyze both historical and real-time data to predict potential failures, performance issues, or resource demands. By automating tasks like capacity planning and incident detection, teams can cut down on downtime and reduce mean time to resolution (MTTR). This allows SRE teams to shift their focus toward managing reliability proactively while keeping systems stable and using resources efficiently.